In my last post, I discussed phase transitions, and how computing the free energy for a model would let you work out the phase diagram. Today, I want to discuss in more detail some methods for computing free energies.
The most popular tool physicists use for computing free energies is “mean-field theory.” There seems to be at least one “mean-field theory” for every model in physics. When I was a graduate student, I became very unhappy with the derivations for mean-field theory, not because there were not any, but because there were too many! Every different book or paper had a different derivation, but I didn’t particularly like any of them, because none of them told you how to correct mean-field theory. That seemed strange because mean-field theory is known to only give approximate answers. It seemed to me that a proper derivation of mean-field theory would let you systematically correct the errors.
One paper really made me think hard about the problem; the famous 1977 “TAP” spin glass paper by Thouless, Anderson, and Palmer. They presented a mean-field free energy for the Sherrington-Kirkpatrick (SK) model of spin glasses by “fait accompli,” which added a weird “Onsager reaction term” to the ordinary free energy. This shocked me; maybe they were smart enough to write down free energies by fait accompli, but I needed some reliable mechanical method.
Since the Onsager reaction term had an extra power of 1/T compared to the ordinary energy term in the mean field theory, and the ordinary energy term had an extra power of 1/T compared to the entropy term, it looked to me like perhaps the TAP free energy could be derived from a high-temperature expansion. It would have to be a strange high-temperature expansion though, because it would need to be valid in the low-temperature phase!
Together with Antoine Georges, I worked out that the “high-temperature” expansion (it might better be thought of as a “weak interaction expansion”) could in fact be valid in a low-temperature phase, if one computed the free energy at fixed non-zero magnetization. This turned out to be the key idea; once we had it, it was just a matter of introducing Lagrange multipliers and doing some work to compute the details.
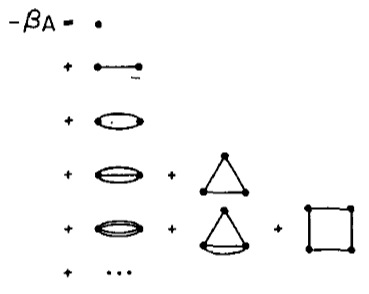
It turned out that ordinary mean-field theory is just the first couple terms in a Taylor expansion. Computing more terms lets you systematically correct mean field theory, and thus compute the critical temperature of the Ising model, or any other quantities of interest, to better and better precision. The picture above is a figure from the paper, representing the expansion in a diagrammatic way.
We found out, after doing our computations but before submitting the paper, that in 1982 Plefka had already derived the TAP free energy for the SK model from that Taylor expansion, but for whatever reason, he had not gone beyond the Onsager correction term or noted that this was a technique that was much more general than the SK model for spin glasses, so nobody else had followed up using this approach.
If you want to learn more about this method for computing free energies, please read my paper (with Antoine Georges) “How to Expand Around Mean-Field Theory Using High Temperature Expansions,” or my paper “An Idiosyncratic Journey Beyond Mean Field Theory.”
This approach has some advantages and disadvantages compared with the belief propagation approach (and related Bethe free energy) which is much more popular in the electrical engineering and computer science communities. One advantage is that the free energy in the high-temperature expansion approach is just a function of simple one-node “beliefs” (the magnetizations), so it is computationally simpler to deal with than the Bethe free energy and belief propagation. Another advantage is that you can make systematic corrections; belief propagation can also be corrected with generalized belief propagation, but the procedure is less automatic. Disadvantages include the fact that the free energy is only exact for tree-like graphs if you add up an infinite number of terms, and the theory has not yet been formulated in an nice way for “hard” (infinite energy) constraints.
If you’re interested in quantum systems like e.g. the Hubbard model, the expansion approach has the advantage that it can also be applied to them; see my paper with Georges, or the lectures by Georges on his related “Dynamical Mean Field Theory,” or this recent paper by Plefka, who has returned to the subject more than 20 years after his original paper.
Also, if you’re interested in learning more about spin glasses or other disordered systems, or about other variational derivations for mean-field theory, please see this post.








