I recently moved to Analog Devices, where I am Director of AI Research. My current research focus is on the design and hardware implementation of novel machine learning and inference algorithms. I also direct the a group of about twenty very talented researchers in Algorithmic Systems Group at the Analog Garage Research Lab. Our group creates advanced algorithms in the fields of signal processing, machine learning, and AI, and implements those algorithms in practical and efficient hardware. We are growing, so if you are interested in joining, and have skills in at least two of the following areas: signal processing, machine learning, algorithm development, ASIC circuit design, FPGA prototyping, and software development, and have or will soon have a Ph.D. or equivalent experience, please write to me.
Archive for the ‘Science’ Category
Move to Analog Devices
January 17, 2016Move to Disney Research
January 29, 2012I’m checking in for the first time in a long time just to let you know that in 2011, I moved from MERL to Disney Research. At Disney Research, I’ve been working on AI and machine learning. I’m enjoying it a lot, and expect to be giving several talks on my research soon.
You can now find my publications and other professional information at my personal web-page.
Connect6
October 23, 2007
I’ve been enjoying playing the game Connect6 with my son Adam. The game was invented and introduced by Professor I-Chen Wu, from National Chiao Tung University in Taiwan. Connect6 is played with a Go board and stones. The object is to place six stones in a row, diagonally, horizontally, or vertically. On the first turn, Black places a single stone; after that each player places two stones per turn. Because each player will always have placed one more stone than his or her opponent after each turn, the game appears to be balanced.
One potential concern about this notion of balance is that perhaps the second player should place his or her stones far from the first stone, to get a two-stone advantage somewhere else on the board, and possibly forcing the first player to follow in that part of the board. Fortunately, Wu and a colleague demonstrated that this initial break-away strategy is unlikely to be good for White in this paper.
Anyways, it’s not clear whether with perfect play the game should be a win for the first player, a win for the second player, or a draw (with neither player ever able to achieve six-in-a-row.) If I had to guess, I would venture a draw, even on an infinite board, but on the other hand my actual games have all ended in victory for somebody.
The game is very similar to Gomoku (also known as Connect 5), where one tries to get five stones in a row, but each player only places one stone at a time. Of course, that game favors the first player, and in fact it has apparently been demonstrated that the first player wins with perfect play.
Renju is an older and much less elegant approach to balancing Gomoku. In Renju, the first player is restricted from making moves which make certain types of threats. Looking at all the complications in the Renju rules, I find it surprising that it took so long for Connect6 to be introduced.
In fact, aside from the issues of fairness and elegance of rules, I also find that Connect6 has a more dynamic feel than Gomoku or Renju; I definitely prefer it.
Because of the large number of possible moves each side can make each turn, and the difficulty of evaluating a position, it’s not easy to program a computer to play Connect6 well; I don’t think any programs exist yet that play as well as humans. You can play Connect6 against some relatively weak bots and other humans at Vying Games, which also features other interesting turn-based strategy games (currently Checkers, Pente, Keryo-Pente, Phutball, Breakthrough, Othello, Kalah, Oware, and Footsteps).
2008 SIAM Annual Meeting
October 22, 2007Lenore Cowen (a co-chair of the 2008 SIAM annual meeting) asked if I might write a post here to help publicize that conference, and I’m very happy to do so. The conference will be held in San Diego from July 7-11, and it looks like it will cover a wider spectrum of topics than is usual for SIAM, so you might consider attending even if it’s not on your normal conference circuit.
The themes for the 2008 meeting are computational science & engineering, data mining, dynamical systems, geosciences, imaging science, linear & multi-linear algebra, biological, social, and internet networks, and enabling complex simulations with scientific software. There is also a quite diverse list of invited speakers.
At SIAM’s annual meeting you are encouraged to propose and organize your own mini-symposium. There are also regular contributed talks and posters. Submission deadlines are January 14 for minisymposium proposals, and January 28 for abstracts for contributed and minisymposium speakers. See the conference web-site for more details.
Using Unambiguous Notation
October 19, 2007I’ve mentioned their book the “Structure and Interpretation of Classical Mechanics” a couple times already; today I’d like to recommend that you read a wonderful short paper by Gerald Jay Sussman and Jack Wisdom, called “The Role of Programming in the Formulation of Ideas,” which helps explain why understanding physics and the other mathematical sciences can sometimes be so difficult. The basic point is that our notation is often an absolute mess, caused by the fact that we use equations like we use natural language, in a highly ambiguous way:
“It is necessary to present the science in the language of mathematics. Unfortunately, when we teach science we use the language of mathematics in the same way that we use our natural language. We depend upon a vast amount of shared knowledge and culture, and we only sketch an idea using mathematical idioms.”
The solution proposed is to develop notation that can be understood by computers, which do not tolerate ambiguity:
“One way to become aware of the precision required to unambiguously communicate a mathematical idea is to program it for a computer. Rather than using canned programs purely as an aid to visualization or numerical computation, we use computer programming in a functional style to encourage clear thinking. Programming forces one to be precise and formal, without being excessively rigorous. The computer does not tolerate vague descriptions or incomplete constructions. Thus the act of programming makes one keenly aware of one’s errors of reasoning or unsupported conclusions.”
Sussman and Wisdom then focus on one highly illuminating example, the Lagrange equations. These equations can be derived from the fundamental principle of least action. This principle tells you that if you have a classical system that begins in a configuration C1 at time t1 and arrives at a configuration C2 at time t2, the path it traces out between t1 and t2 will be the one that is consistent with the initial and final configurations and minimizes the integral over time of the Lagrangian for the system, where the Lagrangian is given by the kinetic energy minus the potential energy.
Physics textbooks tell us that if we apply the calculus of variations to the integral of the Lagrangian (called the “action”) we can derive that the true path satisfies the Lagrange equations, which are traditionally written as:
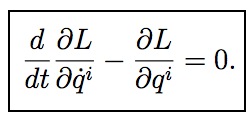
Here L is the Lagrangian, t is the time, annd qi are the coordinates of the system.
These equations (and many others like them) have confused and bewildered generations of physics students. What is the problem? Well, there are all sorts of fundamental problems in interpreting these equations, detailed in Sussman and Wisdom’s paper. As they point out, basic assumptions like whether a coordinate and its derivative are independent variables are not consistent within the same equation. And shouldn’t this equation refer to the path somewhere, since the Lagrange equations are only correct for the true path? I’ll let you read Sussman and Wisdom’s full laundry list of problems yourself. But let’s turn to the psychological effects of using such equations:
“Though such statements (and derivations that depend upon them) seem very strange to students, they are told that if they think about them harder they will understand. So the student must either come to the conclusion that he/she is dumb and just accepts it, or that the derivation is correct, with some appropriate internal rationalization. Students often learn to carry out these manipulations without really understanding what they are doing.”
Is this true? I believe it certainly is (my wife agrees: she gave up on mathematics, even though she always received excellent grades, because she never felt she truly understood). The students who learn to successfully rationalize such ambiguous equations, and forget about the equations that they can’t understand at all, are the ones who might go on to be successful physicists. Here’s an example, from the review of Sussman and Wisdom’s book by Piet Hut, a very well-regarded physicist who is now a professor at the Institute for Advanced Studies:
“… I went through the library in search of books on the variational principle in classical mechanics. I found several heavy tomes, borrowed them all, and started on the one that looked most attractive. Alas, it didn’t take long for me to realize that there was quite a bit of hand-waving involved. There was no clear definition of the procedure used for computing path integrals, let alone for the operations of differentiating them in various ways, by using partial derivatives and/or using an ordinary derivative along a particular path. And when and why the end points of the various paths had to be considered fixed or open to variation also was unclear, contributing to the overall confusion.
Working through the canned exercises was not very difficult, and from an instrumental point of view, my book was quite clear, as long as the reader would stick to simple examples. But the ambiguity of the presentation frustrated me, and I started scanning through other, even more detailed books. Alas, nowhere did I find the clarity that I desired, and after a few months I simply gave up. Like generations of students before me, I reluctantly accepted the dictum that ‘you should not try to understand quantum mechanics, since that will lead you astray for doing physics’, and going even further, I also gave up trying to really understand classical mechanics! Psychological defense mechanisms turned my bitter sense of disappointment into a dull sense of disenchantment.”
Sussman and Wisdom do show how the ambiguous conventional notation can be replaced with unambiguous notation that can even be used to program a computer. Because it’s new, it will feel alien at first; the Lagrange equations look like this:

It’s worth learning Sussman and Wisdom’s notation for the clarity it ultimately provides. It’s even more important to learn to always strive for clear understanding.
One final point: although mathematicians do often use notation that is superior to physicists’, they shouldn’t feel too smug; Sussman and Wisdom had similar things to say about differential geometry in this paper.
SICM on Mac OS X
October 17, 2007“Structure and Interpretation of Classical Mechanics,” (SICM) by Gerald Jay Sussman and Jack Wisdom, with Meinhard Mayer, is a fascinating book, revisiting classical mechanics from the point of view that everything must be computationally explicit. I already mentioned the book in a previous post.
The book is available online, and all the software is freely available on-line as well. The software is written in Scheme, and a very extensive library called “scmutils” was developed to support computations in classical mechanics, including implementations of many symbolic and numerical algorithms.
I think that many scientists and programmers could find the “scmutils” library to be generally useful, even if they are not particularly interested in classical mechanics. If you are using the GNU/Linux operating system, there’s no problem in getting the library working. However, if you want to use it on Mac OS X (or Windows), the instructions leave the impression that it’s not possible, and Googling turned up some useful information, but no complete instructions, and also some people that seemed to be at a loss about how to do it.
Well, it is possible to get MIT-Scheme with the scmutils library running on Mac OS X (and you can probably modify my instructions to make it work on Windows too):
Click here for my instructions for running scmutils on Mac OS X.
NobelPrize.org
October 16, 2007
It’s Nobel season, as you’ve certainly noticed. What you might be less aware of is that the Nobel Foundation maintains an interesting web-site at http://nobelprize.org/. Since 2001, all the Nobel lectures have been video-taped, and the videos are all available at the site. Each of the Nobel Laureates since 2001 has also been interviewed, and since 2004, the Nobel Laureates in physics, medicine, chemistry and economics have participated in round-table discussions, and there have been documentaries produced about each of the Laureates. So there’s quite a lot of material to view for all tastes and scientific interests.
The site is a little awkwardly organized, but you can find your way around. As one random starting point that might be of interest, here’s the page about the 2006 Prize in Medicine, to Andrew Fire and Craig Mello, for the discovery of RNA interference.
While on the subject of the Nobel Prize, I can’t resist adding the priceless reaction of Doris Lessing, this year’s Nobel Laureate in Literature, to learning that she won the prize.
LDPC Decoders and PyCodes
October 15, 2007I already wrote about Gallager’s LDPC error-correcting codes, but I didn’t explain very much about how they work, aside from pointing you to some good references. I want to use this post to say a little about their decoders, which use the belief propagation algorithm, and also to make you aware of some freely available LDPC software, in case you want to study or simulate these codes.
The decoders typically work by message-passing (although decoders based on linear programming have also been studied). One represents the codes using a “Tanner graph,” that looks like the figure shown below, which is actually a Tanner graph for the famous Hamming code.
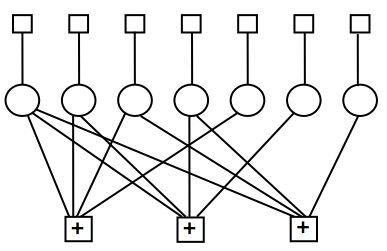
The circles in the Tanner graph represent the bits that are transmitted. For this Hamming code, only 7 bits are transmitted in a block, but more practical codes will have hundreds or thousands of bits in a block.
The squares with a “+” inside of them represent the parity check constraints. Each parity check constraint enforces that the bits that it is connected to must sum to 0 modulo 2, or equivalently the sum of the bits is even. For example, in the code above, there are three parity check constraints, and the first parity check constraint forces the first, second, third, plus fifth bit to sum to an even number. Even in codes with large number of bits, each check will only be connected to a small number of bits; that’s what makes the codes “low density.”
The plain squares represent the information from the channel about each bit. For example, if a binary symmetric channel with a flip probability of f was used, and the first bit was received as a 0, the first square would be a function that said that the first bit had a probability of 1-f of being a 0, and a probability of f of being a 1.
The belief propagation decoders for LDPC codes (there are actually various variants) work by passing messages back and forth between the bit nodes and the parity check nodes in the factor graph. The bit nodes start by sending their beliefs about what values they have to their neighboring check nodes. I.e., a message would say something like “bit 1 believes it has a 90% chance of being a 0, and a 10% chance of being a 1.”
The check nodes look at their incoming messages, and send out appropriate messages in response. For example, if a check node is connected to four bits, and the first three bits think that they are a 0, a 0, and a 1, respectively, the fourth bit will get a message to be a 1 (so that the sum will be even), with a probability that depends on how strongly the three other bits believe that they have those values.
When the bits get messages back from the check nodes, they update their beliefs appropriately and iterate. Eventually, if we’re lucky, the bits have beliefs which are consistent (when they are thresholded to their most likely value) with all the parity checks, and the decoder can output a codeword. Again, you should check out the references in my previous post about LDPC codes for more mathematical details about the algorithms.
If you want to implement LDPC codes, you might want to use the PyCodes package developed by Dr. Emin Martinian while he was at Mitsubishi Electric Research Labs (MERL). PyCodes is written in C, and linked into Python, so you can call it within Python as an ordinary module, but it still runs very fast.
Emin began writing PyCodes when he was my intern, and continued when he became a full-time employee at MERL. It’s very well-written code that I use a lot; Emin was a professional software developer before he was a graduate student, and the software is professional-quality. PyCodes is free for non-commercial use; see the license for more details.
For other software for error-correcting codes, see “the Error Correcting Codes Page.”
On Blogs and Books
October 12, 2007Jeff Atwood has a great blog, called “Coding Horror,” about software development. He’s been blogging continuously and very actively since 2004, which I find impressive; check out his archives.
One of his most recent posts is about the book that he’s just completed, on ASP.NET. I can’t say that I’m interested in the subject of his book, but I was interested in what he had to say about writing blogs versus writing books. Basically, he comes down heavily in favor of writing blogs:
“As I see it, for the kind of technical content we’re talking about, the online world of bits completely trumps the offline world of atoms:
- it’s forever searchable
- you, not your publisher, will own it
- it’s instantly available to anyone, anywhere in the world
- it can be cut and pasted; it can be downloaded; it can even be interactive
- it can potentially generate ad revenue for you in perpetuity
And here’s the best part: you can always opt to create a print version of your online content, and instantly get the best of both worlds. But it only makes sense in that order. Writing a book may seem like a worthy goal, but your time will be better spent channeling the massive effort of a book into creating content online.”
He also points out that writing books is a lot harder than writing blogs:
“Writing a book is hard work. For me, writing blog entries feels completely organic, like a natural byproduct of what I already do. It’s not effortless by any means, but it’s enjoyable. I can put a little effort in, and get immediate results out after I publish the entry. The book writing process is far more restrictive. Instead of researching and writing about whatever you find interesting at any given time, you’re artificially limited to a series of chapters that fit the theme of the book. You slave away for your publisher, writing for weeks on end, and you’ll have nothing to show for it until the book appears (optimistically) six months down the road. Writing a book felt a lot like old fashioned hard work– of the indentured servitude kind.”
Charles Petzold, an experienced author of programming texts, chimes in here with more details on the declining economics of technical book-writing. Apparently a lot fewer people are buying programming books nowadays, so the financial situation for the authors of these books is getting worse. So Petzold agrees that it makes a lot more sense to write in blog format, but notes that blogs don’t usually pay very well.
Let me just give a different perspective, from someone who is more interested in academic writing than technical writing. I think that most academics don’t write books in order to make money, and that’s certainly true of the journal articles that are written. So for academics, moving from books to blogs has more of the upside and less of the downside than for other authors.
I know that I personally find writing a blog a lot more appealing than writing a book. As Atwood points out, you can write about whatever happens to appeal to you on the day you’re writing; and you get much faster feedback. Sure it’s some work, but all in all, it’s great!
Petzold has another criticism of blogs:
On the Internet, everything is in tiny pieces. The typical online article or blog entry is 500, 1000, maybe 1500 words long. Sometimes somebody will write an extended “tutorial” on a topic, possibly 3,000 words in length, maybe even 5,000.
It’s easy to convince oneself that these bite-sized chunks of prose represent the optimum level of information granularity. It is part of the utopian vision of the web that this plethora of loosely-linked pages synergistically becomes all the information we need.
This illusion is affecting the way we learn, and I fear that we’re not getting the broader, more comprehensive overview that only a book can provide. A good author will encounter an unwieldy jungle of information and cut a coherent path through it, primarily by imposing a kind of narrative over the material. This is certainly true of works of history, biography, science, mathematics, philosophy, and so forth, and it is true of programming tutorials as well.
Sometimes you see somebody attempting to construct a tutorial narrative by providing a series a successive links to different web pages, but it never really works well because it lacks an author who has spent many months (or a year or more) primarily structuring the material into a narrative form.
For example, suppose you wanted to learn about the American Civil War. You certainly have plenty of online access to Wikipedia articles, blog entries, even scholarly articles. But I suggest that assembling all the pieces into a coherent whole is something best handled by a trained professional, and that’s why reading a book such as James McPherson’s Battle Cry of Freedom will give you a much better grasp of the American Civil War than hundreds of disparate articles.
If I sound elitist, it’s only because the time and difficulty required for wrapping a complex topic into a coherent narrative is often underestimated by those who have never done it. A book is not 150 successive blog entries, just like a novel isn’t 150 character sketches, descriptions, and scraps of dialog.”
As somebody who writes blog posts that typically come in at 500-1500 words, but loves to read books, I want to respond to that.
The web lets us write material in whatever form we want. I’m comfortable with the 500-1500 word post. Other people with popular blogs write 2-sentence posts linking to an article. Paul Graham writes long essays. David MacKay puts drafts of his books online.
The fact is, that you can write about whatever you want, whenever you want, in whatever form you want. The most important point is that you don’t need permission to publish anymore. You don’t need a publisher; you are the publisher.
Which brings me to a related point. I find a lot of the current scientific publication process completely bizarre. Scientists write the articles, type-set the articles, review the articles, edit the articles, and then find that their own articles are not freely available online? And we write articles that are hard to understand because of space limitations? Online there are no space limitations! The entire system is lumbering on mostly as if we still were living in the early 20th century, when only a few specialized groups of people had the capability to publish, and delivering journal articles to people was necessarily expensive.
Most of the current system’s remaining justification, compared to a free system where everybody simply published their work online, and that was the end of it, is for credentialing articles by peer review and credentialing people by the number of peer-reviewed articles they’ve written. Look, I know peer review is important, but given the huge time sink of the current system, and the morale problems that it contributes to, I think that we should take a closer look at the costs and benefits, and maybe be more open to people who simply publish their work online (see, for example, Perelman’s papers proving the Poincare conjecture, which were never published in a peer-reviewed journal).
So if you feel the urge, publish yourself online in whatever format suits you. Just try to make the content worthwhile for somebody else in the world, and don’t worry about the rest. [End of rant.]
iTunes U
October 11, 2007
I bought one of the new iPod Nanos last week. One of the main reasons that I wanted one was to be able to listen to and watch the video lectures available at iTunes U while walking or traveling. There’s quite a bit of interesting material available for free download. For example, I’ve been watching lectures from the weekly colloquium of the Stanford Computer Systems Laboratory.
There are also MIT courses about graduate-level Digital Communications taught by Edison and Shannon medalist David Forney, or introductory Biology by Eric Lander and Robert Weinberg, or Mathematical Methods for Engineers (look under Mathematics) by Gilbert Strang, all in video. The podcast section of iTunes Store also has many videos of entertaining 20-minute talks from the TED conferences held over the last few years.
Of course there’s all sorts of other material available; I’m just pointing out some more academic videos.
It’s somewhat annoying how difficult it is to find specifically video material; there’s much more material available only as audio, but the video material is not really specifically singled out in any way. Also, you should know that you can also watch all the material directly on your computer, but if you want to do that, you should also visit this MIT OpenCourseWare page or this Berkeley webcast page. Both of these pages have a lot of additional video courses available in formats other than the MP4 format used by the iPod.
The iPod nano is very small and light. It’s my first iPod, so I was pleasantly surprised to learn that the earbuds are actually pretty comfortable. The screen is really sharp, but it’s also really tiny, so while it’s OK to look at occasionally to see what’s going on, but I wouldn’t want to watch a long movie on it. The iPod Touch will definitely be a better option for that.


