I already wrote about Gallager’s LDPC error-correcting codes, but I didn’t explain very much about how they work, aside from pointing you to some good references. I want to use this post to say a little about their decoders, which use the belief propagation algorithm, and also to make you aware of some freely available LDPC software, in case you want to study or simulate these codes.
The decoders typically work by message-passing (although decoders based on linear programming have also been studied). One represents the codes using a “Tanner graph,” that looks like the figure shown below, which is actually a Tanner graph for the famous Hamming code.
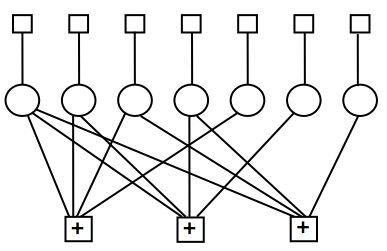
The circles in the Tanner graph represent the bits that are transmitted. For this Hamming code, only 7 bits are transmitted in a block, but more practical codes will have hundreds or thousands of bits in a block.
The squares with a “+” inside of them represent the parity check constraints. Each parity check constraint enforces that the bits that it is connected to must sum to 0 modulo 2, or equivalently the sum of the bits is even. For example, in the code above, there are three parity check constraints, and the first parity check constraint forces the first, second, third, plus fifth bit to sum to an even number. Even in codes with large number of bits, each check will only be connected to a small number of bits; that’s what makes the codes “low density.”
The plain squares represent the information from the channel about each bit. For example, if a binary symmetric channel with a flip probability of f was used, and the first bit was received as a 0, the first square would be a function that said that the first bit had a probability of 1-f of being a 0, and a probability of f of being a 1.
The belief propagation decoders for LDPC codes (there are actually various variants) work by passing messages back and forth between the bit nodes and the parity check nodes in the factor graph. The bit nodes start by sending their beliefs about what values they have to their neighboring check nodes. I.e., a message would say something like “bit 1 believes it has a 90% chance of being a 0, and a 10% chance of being a 1.”
The check nodes look at their incoming messages, and send out appropriate messages in response. For example, if a check node is connected to four bits, and the first three bits think that they are a 0, a 0, and a 1, respectively, the fourth bit will get a message to be a 1 (so that the sum will be even), with a probability that depends on how strongly the three other bits believe that they have those values.
When the bits get messages back from the check nodes, they update their beliefs appropriately and iterate. Eventually, if we’re lucky, the bits have beliefs which are consistent (when they are thresholded to their most likely value) with all the parity checks, and the decoder can output a codeword. Again, you should check out the references in my previous post about LDPC codes for more mathematical details about the algorithms.
If you want to implement LDPC codes, you might want to use the PyCodes package developed by Dr. Emin Martinian while he was at Mitsubishi Electric Research Labs (MERL). PyCodes is written in C, and linked into Python, so you can call it within Python as an ordinary module, but it still runs very fast.
Emin began writing PyCodes when he was my intern, and continued when he became a full-time employee at MERL. It’s very well-written code that I use a lot; Emin was a professional software developer before he was a graduate student, and the software is professional-quality. PyCodes is free for non-commercial use; see the license for more details.
For other software for error-correcting codes, see “the Error Correcting Codes Page.”



